
A Brief Introduction to Epistemic Probability

The probability relevant for debates in philosophy of religion is called epistemic probability, which concerns establishing degrees of confidence in an hypothesis. This is the probability having to do with human belief.
Compare: When I say it is improbable (only a 26% chance) any St. Bernard will live to age ten, I am discussing statistical probability. Vs., when I say Lola – my St. Bernard – likely scarfed my daughter’s breakfast when nobody was looking, I am discussing epistemic probability.
Statistical probabilities are determined (as the name implies) by statistical means. We form a sample group of Wisconsinites, ask how many are Republican, then generate the likelihood of any given Wisconsinite being Republican. However, it is not by statistical means that I ought to believe Lola scarfed by daughter’s breakfast when nobody was looking, even though, undoubtedly, it is still based in experience.
Notice the word ought – there is, curiously, a normative element when it comes to epistemic probability. If we were Hilary Clinton, we might call people who don’t accept probable beliefs deplorable.
Finally, statistical probabilities tend to be general — about dogs in general or Wisconsinites in general, etc. — whereas epistemic probabilities tend to be specific — about THIS dog in particular, or the likelihood that THE theory of relativity is true, etc. As usual, these distinctions are not always so clear and convenient. Things become messy, quickly. But this should be enough to start.
Probabilistic reasoning is something we engage on regular basis even when we don’t have an explicit understanding of it. Essentially, when encountering evidence, we ask how expected that evidence is given some hypothesis and form our beliefs accordingly.
Basic example: I walk outside to discover my driveway is wet. Spontaneously, I form the hypothesis that it rained. Why? Because I would expect my driveway to be wet if it rained. However, I notice the wetness is restricted to just around my car. This data is unexpected if it rained; I would expect the entire area to be wet if the “it rained” hypothesis were true. So, I form a new hypothesis: “My wife, God bless her, washed my car. Isn’t she wonderful?” I then peek around the corner to see a bucket of suds. My confidence in this new hypothesis grows — “Why, she really is wonderful!” — because I am noticing more things that I would expect to see if the “my wife washed my car” hypothesis were true and that would be surprising if that hypothesis were not true. Again, all very intuitive.
We can make this more precise by introducing Bayesian probability, which helps us to see whether some experience or data supports a hypothesis by asking two questions:
How expected is some Data (D) given some Hypothesis (H)
Vs.
How expected is some Data (D) without some Hypothesis (H)
In other words, if D is more expected given H than without H, then D supports H.
We’ll save the technical details of Bayes theorem until later. For now, we can get the point through stock example:
Imagine that there are two jars of candy and you cannot see into them. One jar of candy contains 90% Twix and 10% Milky Way. The other jar of candy contains 10% Twix and 90% Milky Way. Each has 100 pieces of candy in total.
At random, you decide to pull one piece of candy from one of the jars.
You pull a Twix.
What jar do you think that candy was pulled from?
Probably, you think it was pulled from the first jar. It just seems that hitting a Twix is evidence for “this is the majority Twix candy jar” than for “this is the majority Milky Way candy jar.” Hence why hitting a Twix causes you to favor the hypothesis “I pulled from the majority Twix candy jar.” Of course, we still know that you may have pulled the Twix from the majority Milky Way candy jar, but nevertheless given that a Twix was pulled we know, probabilistically, which way to lean.
Said differently: pulling a Twix counts as evidence for the hypothesis that you pulled from the majority Twix candy jar (call that Hypothesis T, or Ht for short) and evidence against the hypothesis that you pulled from the majority Milky Way candy jar (call that Hypothesis M, or Hm for short).
What we want to know now is how confident should we be in the hypothesis we’re favoring? 100% confident? Or just a little bit?
We can figure this out in stages. First, imagine there is an alien observer who knows you’re pulling from the majority Twix Candy jar. This alien also knows (and this we say is part of our “background knowledge”) that you don’t have a magic Twix-sensing glove, which is to say your selection is random. We can then ask what degree of confidence should this alien observer have in your pulling a Twix from that jar? In other words, how expected is pulling a Twix if – if, if, if! – Ht is true.
The answer is basic math: 90%. Which is to say the epistemic probability of E (pulling a Twix) given Ht is 9/10. We can abbreviate this as: P(E/Ht) = .9, which reads “the probability of E given Ht is 90%.”.
That point made about background knowledge is critical. If the alien knew you had a Twix-sensing glove, this would throw everything off. Commonly, we include a term (abbreviated K) in our assessment that is meant to list the relevant background knowledge. Relevant to our example, we can say the alien observer knows that you were picking blinding and didn’t have a special Twix-sensing glove (would be pretty sweet) – which leaves the assessment where it was: the alien observer should have a .9 level of confidence that you draw a Twix from the Majority Twix candy jar. Abbreviate this as P(E/Ht&K) = .9, which reads “the probability of E given Ht and K is 90%.”
So far so good? SO WHAT, says Megadeth.
We’re only about halfway done. We still haven’t answered the original question, which was how confident YOU should be in Ht given that you pulled a Twix (not how confident an alien observer would be that you pull a Twix given Ht). In other words, we want to know the probability of the hypothesis GIVEN the evidence. And so far, we have only calculated the probability of the evidence GIVEN the hypothesis. What we need is some way to relate the two. Famously, that is where Bayes’ Theorem comes in:

Let’s break this down.
P(Ht/K) is our prior probability, which is the confidence you should have in Ht given the background knowledge but WITHOUT the evidence of drawing a piece of candy. In our example, we can estimate the prior probability to be ½ because we assume a blind draw between two jars of candy and no reason to think one would be favored more than the other. It would be arbitrary in our situation to assign a higher confidence to one hypothesis over another.
We’ve already calculated P(E/Hr&K) = .9. So, the top line should read .5 x .9.
The final calculation is P(E/K) which is asking what level of confidence should be assigned to the proposition “you will draw a Twix” given background knowledge but WITHOUT knowing what was drawn OR what hypothesis is true. This calculation is longer since we must SUM (the prior probability multiplied by the probability that you would draw a Twix given you picked from the Majority Twix jar = .5 x .9) WITH (the prior probability multiplied by the probability that you draw a Twix given you picked from the Majority Milky Way jar = .5 x .1). Run the math and this turns out to be .5.
Now plug everything into Bayes theorem: (.5 x .9)/.5 = .9. And there we go. P(Ht/E&K) = .9, which means we should assign a 90% confidence in the “I pulled from the Majority Twix candy jar” hypothesis, or Ht.
Naturally, this is a clean example, whereas listing background knowledge and assigning prior probability is not always easy or convenient. Imperfect as this tool of reasoning may be, however, in less contrived situations, it is still remarkably powerful.
For example, to show how even in a more complex situation we can maintain an extremely high level of confidence in some hypothesis given the evidence, let’s consider the argument from physical fine-tuning, often used to support a theistic – rather than naturalistic – metaphysic.
Here we’ll borrow from philosopher Michael Rota and focus on just one element of fine-tuning: the cosmological constant.
Rota gives us:
E = The effective cosmological constant falls within the life-permitting range.
Hd = An intelligent being was involved in the production of our universe.
H~d = It is not the case that an intelligent being was involved in the production of our universe.
Background knowledge includes the (conservatively estimated) proposition that the cosmological constant COULD have fallen within a very wide range of values – a range at least 10^41 wider than the life-permitting range.
The tricky part is assigning prior probability. Namely, what degree of confidence should we have in God creating a finely-tuned universe? While it is impossible to give a definite numeric value, several considerations immediately suggest themselves. First, is that God – in virtue of God’s perfection – would obviously see the inherent goodness in creating beings like us. And beings like us depend upon physical fine-tuning. Right away, this gives us a strong logic-based reason to think fine-tuning is not unlikely if God exists, because God would have reason to aim for our existence. As well, God – in virtue of God’s perfection – has that ability. But again: just how confident should we be? Personally, like Rota, I feel it is probably AT LEAST 50% likely. But here’s the thing about this argument: we can grant a ton toward our skeptical friends, since through Bayes Theorem we can see that even if we thought it was just ONE IN ONE BILLION CHANCE that God would produce a finely-tuned universe, we should still be EXTREMELY CONFIDENT in the God hypothesis, given how much more unlikely that evidence is expected absent an intelligent designer.
To see why, let’s follow Rota for the extended demonstration:
“To rely only on a premise that even a skeptic could agree to, let’s be generous and assume P(E/Hd&K) = 1 in a billion, i.e., 1/10^9. The reader may be surprised to learn that, even so, the fine-tuning argument will be exceedingly strong. Starting with the equation (1), a little calculation shows that:

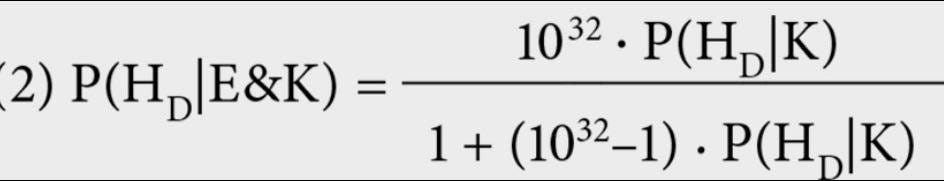
“… This equation relates the rational level of confidence to have in the designer hypothesis given everything relevant we know except for E – this is the so c-called prior probability, P(Hd/K) – to the rational level of confidence to have in the designer hypothesis given everything relevant we know included E – this is the so-called posterior probability P(Hd/E&K). Different people will have different estimates of the prior probability of a universe designer. If you have a strong intuitive sense of the existence of God and you don’t think the evidence against God is very strong, you’ll think P(Hd/K) is relatively high. Although it’s impossible to put a definite numerical value on it, you might still judge the prior probability of the designer hypothesis to be ‘very likely’ or ‘quite likely’ or ‘more likely than not.’ On the other hand, if you lack an intuitive sense of the existence of God and you think the arguments against the existence of God are very strong, you will probably judge P(Hd/K) to be very low. The usefulness of equation (2) is that it shows that it is reasonable to accept the designer hypothesis as nearly certain, even if one started out thinking it was quite unlikely that our universe was produced by an intelligent being. Suppose you start out thinking that the prior probability of the designer hypothesis is .5. Then equation (2) implies you should think, after taking the evidence about the cosmological constant into account, that the probability of the design hypothesis is a virtual certainty, well over .999999. If instead you think P(Hd/K) is 1/10, P(Hd/E&K) Is still over .999999. If P(Hd/K) is 1/10000, P(Hd/K) is still over .999999. Even if one began by thinking that P(Hd/K) is only 1 in 10^28 (which is one in ten thousand trillion trillion), P(Hd/E&K) would still be a bit over .999900. One’s prior probability for the designer hypothesis would have to be all the way down at 1 over 10^32 in order for the posterior probability P(Hd/E&K) to be ½. Taking a moment to think about these numbers will reveal how much the evidence of fine-tuning raising the plausibility of the designer hypothesis.”
What this means is that the theist could grant an extremely charitably victory to the atheist on other probabilistic assessments (for example, the evolutionary argument from evil) but counter that the fine tuning argument can more than pay that probabilistic debt. This is important because most atheists who press the problem of evil against the existence of God probably don’t think it lowers the probability of God’s existence to the ridiculously low levels required to neutralize the force of physical-fine tuning as evidence in favor of God, given the Bayesian analysis.
Nevertheless, this isn’t to say nothing could trump the God hypothesis. There are other considerations. Perhaps, for example, somebody thinks God’s existence is actually impossible. Perhaps, that is, somebody thinks God and evil cannot possibly co-exist, which is something no probability assessment can override. Fortunately, most philosophers these days – theist and atheist alike – agree that the logical form of the problem of evil has been swept into the philosophical dustbin. There just is no contradiction between God and evil; hence, the evidential problem of evil, which engages the same probabilistic reasoning we’ve been examining here.
The remarkable thing is that just so long as somebody doesn’t think the amount of suffering and evil in our world reduces the prior probability of God’s existence below the exceedingly gracious estimates given in the example above (for what it’s worth, I have gone further in suggesting evil is actually better evidence for God rather than away), one should still be extremely confident in God’s existence just from the physical evidence of fine-tuning.
PS - Of course, there are other objections to the fine-tuning argument. Some will posit a multiverse, others will mention selection effect. To my mind, the first objection consistently runs into the issue of either generating contradiction or relocating (and often exacerbating) the problem of fine-tuning, rather than solving it. The second objection confuses explaining fine-tuning with explaining why we stand capable of asking for an explanation of fine-tuning. Whereas one objection relocates the issue, the other objection ignores it.